

Short answer. Your agent never stops because it has no built-in stopping criterion, and the model cannot reliably tell a finished task from an almost-finished one, so it keeps acting. Give the loop a floor and a judge: a hard step budget so it fails loudly instead of running forever, plus a completion check or verifier that decides when the task is actually done. Add loop detection and the runaway becomes a bounded, predictable run.

The agent's loop has no exit. It keeps walking the same ring, repeating steps, because nothing tells it the task is done. Hero image.
Key facts.
- It is one of the most common agent failures: a study of 1,600+ multi-agent failures found step repetition at 15.7%, the single most frequent mode, and "unaware of termination" at 12.4% (Cemri et al., MAST, arXiv:2503.13657, 2025).
- The waste is enormous: an 8B agent averaged 26.4 unnecessary steps out of 40 in the ALFWorld benchmark, looping or issuing ineffective commands instead of stopping (Runaway is Ashamed, But Helpful, arXiv:2505.17616, 2025).
- It is fixable cheaply: the same work shows that adding an early-exit signal, either an injected exit instruction or a verifier that checks task completion, cuts the redundant steps with negligible loss of performance (same paper, 2025).
Why doesn't the agent know when it's done?
Because nothing told it how to know. A traditional program ends when its code returns; an agent runs a loop of think, act, observe, and the only thing that ends it is the agent itself deciding the task is complete. But deciding "done" is a judgment, and the model is often bad at it. It cannot reliably tell a finished task from an almost-finished one, so it keeps acting, re-checking, or trying one more thing. Without an explicit stopping criterion and a budget, the loop has no floor: the agent will keep going, re-reading state, re-calling tools, and spending tokens long after the useful work is done. MAST names this directly as "unaware of termination", and it is one of the top failure modes across frameworks.
What the loops look like
Three shapes, all expensive. The agent repeats the same step, calling the same tool with the same arguments and getting the same result, which MAST found is the single most common failure at 15.7%. It oscillates between two states, undoing and redoing the same change, each step looking locally reasonable. Or it pads the task with ineffective commands, never quite converging. The scale of the waste is striking: in the ALFWorld benchmark, an 8B agent averaged 26.4 unnecessary steps out of 40, meaning most of its run was redundant. Every one of those steps is tokens spent and, in an agent with tools, real actions taken, which is how a stuck agent becomes both a runaway bill and a pile of side effects.
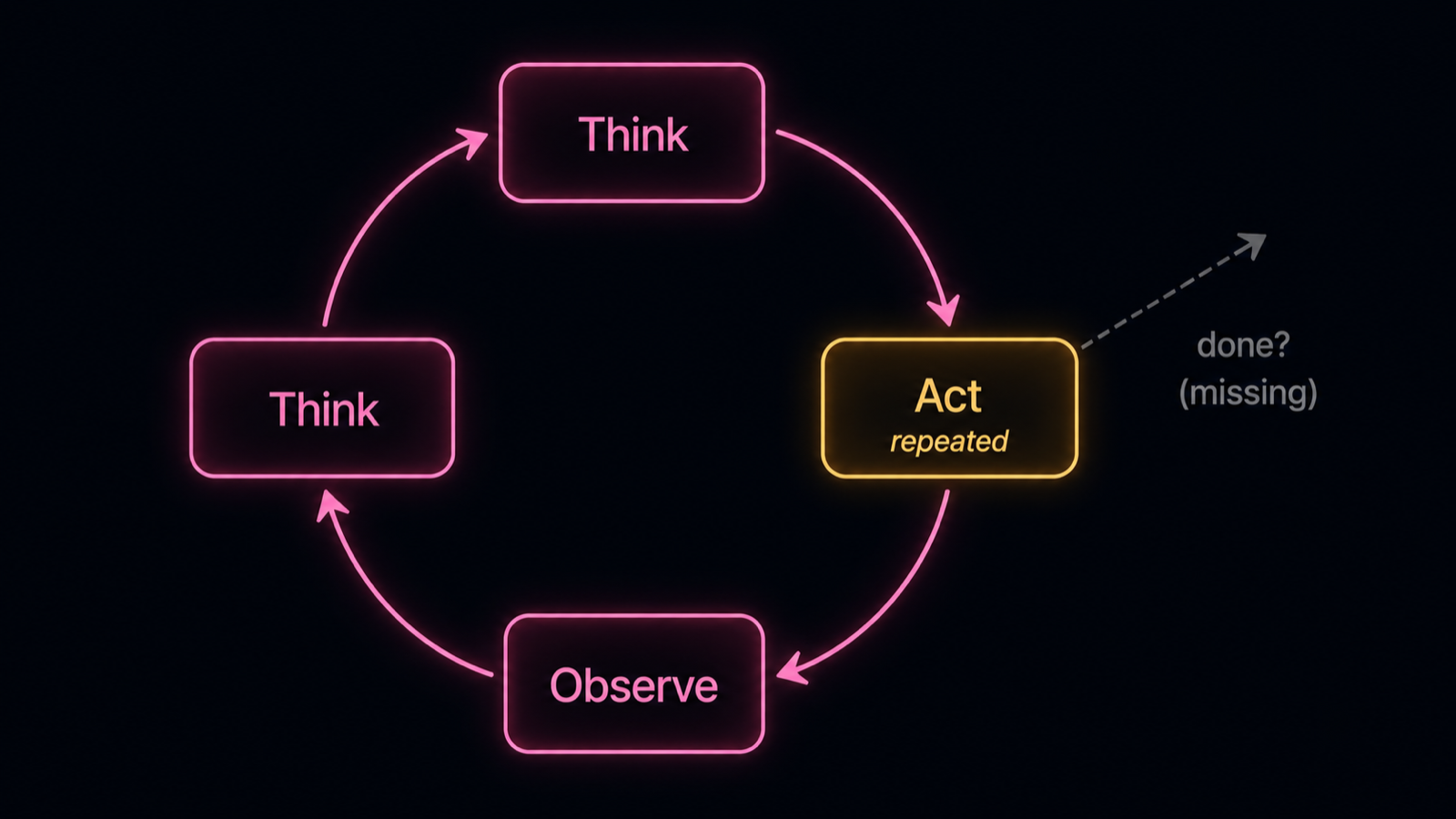
A loop with no exit: think, act, observe, repeat, around the ring, with the 'done?' check that should break it missing. Diagram.
How do you make it stop?
Give the loop a floor and a judge. The floor is a hard step or token budget: cap the number of iterations so a stuck agent fails loudly instead of running forever. The judge is a completion check that is not the agent's own optimism, a verifier, a rule, or a separate model call that decides whether the task is actually done and halts when it is. The early-exit research shows both work, an intrinsic exit signal injected during generation and an extrinsic verifier that checks completion, and that they cut redundant steps with negligible performance loss. Add loop detection that catches a repeated identical action or an A-B-A oscillation and breaks it, and a progress check that stops the agent when it has not advanced in N steps. Together these turn "runs until it gives up or runs out of money" into "stops when done or when bounded."
The pattern is that an agent has no natural end, only the loop you wrap it in, and a model that cannot reliably tell done from not-done will keep going until something stops it. Cap the steps, detect repeated and oscillating actions, check for real progress, and let a verifier decide when the task is complete. None of that is a bigger model, which loops just as confidently. It is a control layer that knows when to stop, which is what VibeModel builds as the Pattern Intelligence Layer.
Frequently asked questions
Why can't the model just decide when it's finished?
Because judging "done" is itself a hard call the model is often miscalibrated on. It cannot reliably distinguish a finished task from a nearly-finished one, so left to itself it keeps acting. MAST tracks this as "unaware of termination", a top failure mode.
Isn't a max-step limit enough?
It is the safety floor, and you should always have one, but on its own it caps the waste rather than fixing it. Pair it with a completion verifier so the agent stops when the task is actually done, not only when it hits the ceiling.
How do I catch a loop early?
Detect repeated identical actions and A-B-A oscillations, and run a progress check: if the agent has not advanced toward the goal in the last few steps, break the loop and escalate. That stops most loops long before the step budget runs out.