


Two embedding models, two coordinate spaces. The same documents land in different geometries, so a query embedded by the new model misses the matches indexed by the old one.
Short answer. Switching embedding models silently breaks retrieval because each model defines its own coordinate space. Your old vectors live in one geometry and the new model's queries live in another, so similarity scores stop meaning anything. If the dimensions happen to match, nothing errors. Results just quietly go wrong until you re-embed the entire corpus with the new model.
Key facts.
- Each embedding model learns a distinct, non-interoperable vector space; a cosine similarity between a query from one model and a vector from another is geometrically meaningless (Qdrant and Weaviate migration docs; OpenAI developer community).
- OpenAI's text-embedding-ada-002 vectors are not compatible with text-embedding-3 vectors; there is no upgrade transform, re-embedding is required (OpenAI developer community, 2024).
- Vector databases enforce a fixed dimension per collection, so a dimension change throws an explicit error, while a same-dimension model swap fails silently instead.
- Re-embedding a large corpus is real work that teams underestimate: one worked example puts a 50-million-document corpus at roughly 25 billion tokens to re-embed (reported, Tensoria 2026).
What does this failure look like in production?
One of two ways. If the new model has a different vector dimension, you get a hard, loud error the moment a query hits the index: dimension X does not match dimension Y. That one is annoying but safe, because it stops you. The dangerous case is when the new model happens to share the old dimension. Then nothing errors. The index accepts the queries, returns its nearest neighbors, and those neighbors are wrong. Recall quietly collapses, the agent starts grounding on irrelevant chunks, and the only symptom is degraded answers that look fluent. Teams often chase the model or the prompt for days before realizing the embedding swap was the cause.
Why are two embedding models incompatible at all?
Because a vector is only meaningful relative to the space it was produced in. Each model is trained with its own architecture, data, and objective, and it encodes meaning as geometry: directions, clusters, angles, and distances that are specific to that model. Two models can both output 1536-dimensional vectors and still place the same sentence in completely different positions, because their axes are rotated and scaled differently. Comparing a query vector from model B against document vectors from model A is like reading GPS coordinates from one map on a totally different map. The numbers compute, the answer is nonsense. There is no reliable linear transform that maps one production embedding space onto another, which is why the only dependable fix is to re-embed.
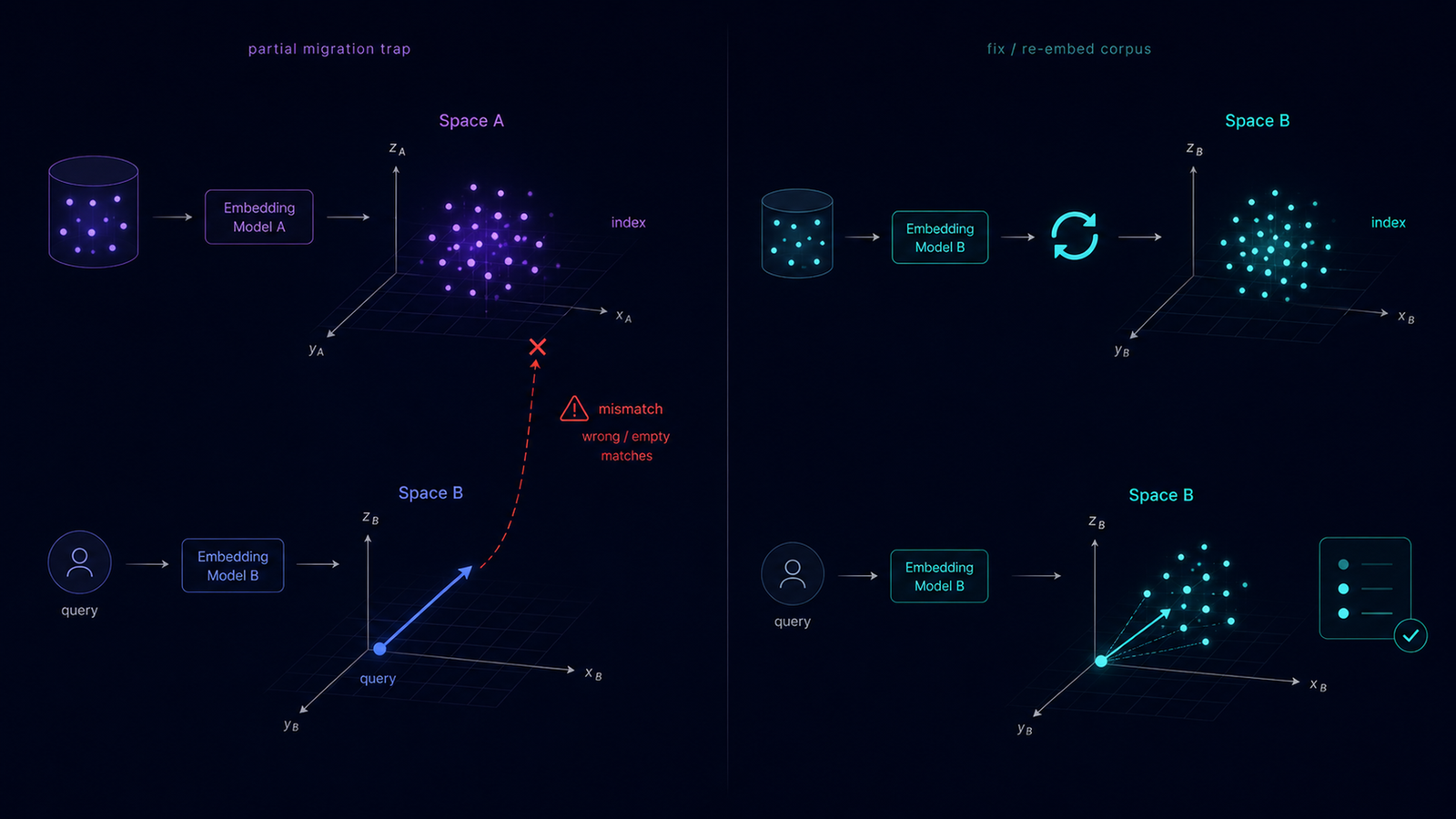
The partial-migration trap: swapping only the query embedder leaves the index in the old space, so every comparison is cross-space and wrong. The fix is to re-embed the corpus into one shared space.
What is the partial-migration trap?
The most common version of this failure is subtle: a developer updates the agent's query embedder to a newer, better model but leaves the existing index, built with the old model, untouched. Now every search embeds the query in space B and compares it against documents in space A. If dimensions differ you get an error; if they match you get silent recall collapse. A nastier variant is provider-side: an embedding API quietly routes to an updated model version, invalidating your whole index with no code change and no error on your side. Both produce plausible-looking but semantically wrong results, and both erode trust without ever crashing.
How do you migrate embedding models safely?
| Risk | Signal | Fix |
|---|---|---|
| Dimension change | Hard "dimension mismatch" error | Re-embed corpus; rebuild index with new dimension |
| Same-dimension swap | Silent recall collapse | Full re-embed; never mix vectors from two models |
| Partial migration | Query embedder newer than index | Version the model with the index; startup assertion |
| Provider silent update | Quality drops with no deploy | Pin model version; monitor retrieval metrics |
The discipline is to treat the embedding model as a versioned dependency of the index, never a swappable black box. Persist your raw chunks separately so re-embedding is just an embed-and-index step. Tag every collection with the exact model and version. Run a blue-green migration: keep the old index serving live traffic while you build and validate the new one, dual-write updates, and cut over only after a golden set of queries clears your Recall@k and nDCG bar. Modern vector databases ship primitives for exactly this (Qdrant named vectors, Weaviate collection aliases) because the problem is common enough to deserve first-class support. Knowing, before you cut over, where the new embeddings hold up and where they degrade is the kind of pattern-level reliability OptimalARC builds as the Pattern Intelligence Layer.
Frequently asked questions
Can I just convert my old vectors to the new model?
No. There is no reliable transform between two production embedding spaces. Research prototypes for unsupervised space translation exist but are not production-ready. Re-embedding the corpus with the new model is the dependable path.
Why did my retrieval break with no error after a model upgrade?
The new model shared the old vector dimension, so the database accepted the queries instead of erroring. It compared new-space queries against old-space vectors, which is meaningless, so it returned wrong neighbors and recall quietly collapsed.
Is it safe to mix old and new vectors in one index?
No. Vectors from two different models are not comparable, so mixing them corrupts similarity search. Keep one model per index, or run separate indexes during a blue-green migration.
How do I catch this before users do?
Version the embedding model alongside the index and add a startup or query-time assertion that fails fast on a mismatch. Track Recall@k and nDCG on a fixed golden query set so a silent drop trips an alert.