

Short answer. Your cost exploded because production tasks are long, and an agent re-sends its entire growing context on every turn. So total tokens climb faster than the step count, not in step with it. A pilot runs a short happy path, a few turns, a small bill. Production runs the long real path, dozens of turns, retries, and tool fan-out, and the same per-step price compounds. The fix is to control how much context each step carries, not to find a cheaper model.

Same agent, same price per token. The pilot is short so the bill is small. The production task is long, and re-sent context stacks turn over turn into a steep curve.
Key facts.
- In a naive agent loop, every call re-sends the conversation so far, so cumulative cost grows roughly with tokens times the number of calls, not linearly with steps. In one real coding session cache reads were 87% of the total cost by the end, and crossed half the cost at 27,500 tokens (Zeyliger, Expensively Quadratic, exe.dev, 2026).
- Agents typically use about 4x more tokens than a chat, and multi-agent systems about 15x more; token usage alone explained 80% of the performance variance on Anthropic's research eval (Anthropic, How we built our multi-agent research system, 2025).
- "The gap between prototype and production is often wider than anticipated," because errors compound across long, stateful runs (Anthropic, same source, 2025).
- Production bills are landing hard: Uber blew through its entire 2026 AI coding budget by April, and one analysis found heavy users spent about 10x the tokens of lighter users for roughly 2x the output (reported, Bellan, TechCrunch, 2026).
Why does cost grow faster than the number of steps?
Because an agent has no working memory of its own. On every turn it re-sends the entire conversation so far, the system prompt, the tool definitions, every prior thought and tool result, then adds the new step on top. Step 20 does not pay for one step of work. It pays to re-read everything from steps 1 through 19 again. So as the task runs longer, the billed input is roughly the running token count multiplied by the number of calls, which curves upward instead of rising in a straight line. The exe.dev analysis of a real coding session put it plainly: cache reads, the cost of re-reading history, crossed half the bill at 27,500 tokens and reached 87% of the total by the end. The price per token never changed. The amount of context being re-sent did.
Why was the pilot so cheap then?
Because the pilot was short, and short is where this math is forgiving. A demo runs the happy path: a clean question, three or four turns, a tidy answer, done before the re-sent context ever stacks up. That is a real measurement, but of a small slice of the curve. Production runs the part of the curve the demo never touched. Real tasks need more turns, hit ambiguity, trigger retries, and fan out into multiple tool calls. Anthropic measured agents using about 4x the tokens of a chat, and multi-agent setups about 15x, with token usage alone explaining 80% of the performance variance on their research eval. Capability and cost ride the same axis. The pilot bought you a glimpse of the bottom of the curve, then production handed you the rest of it.
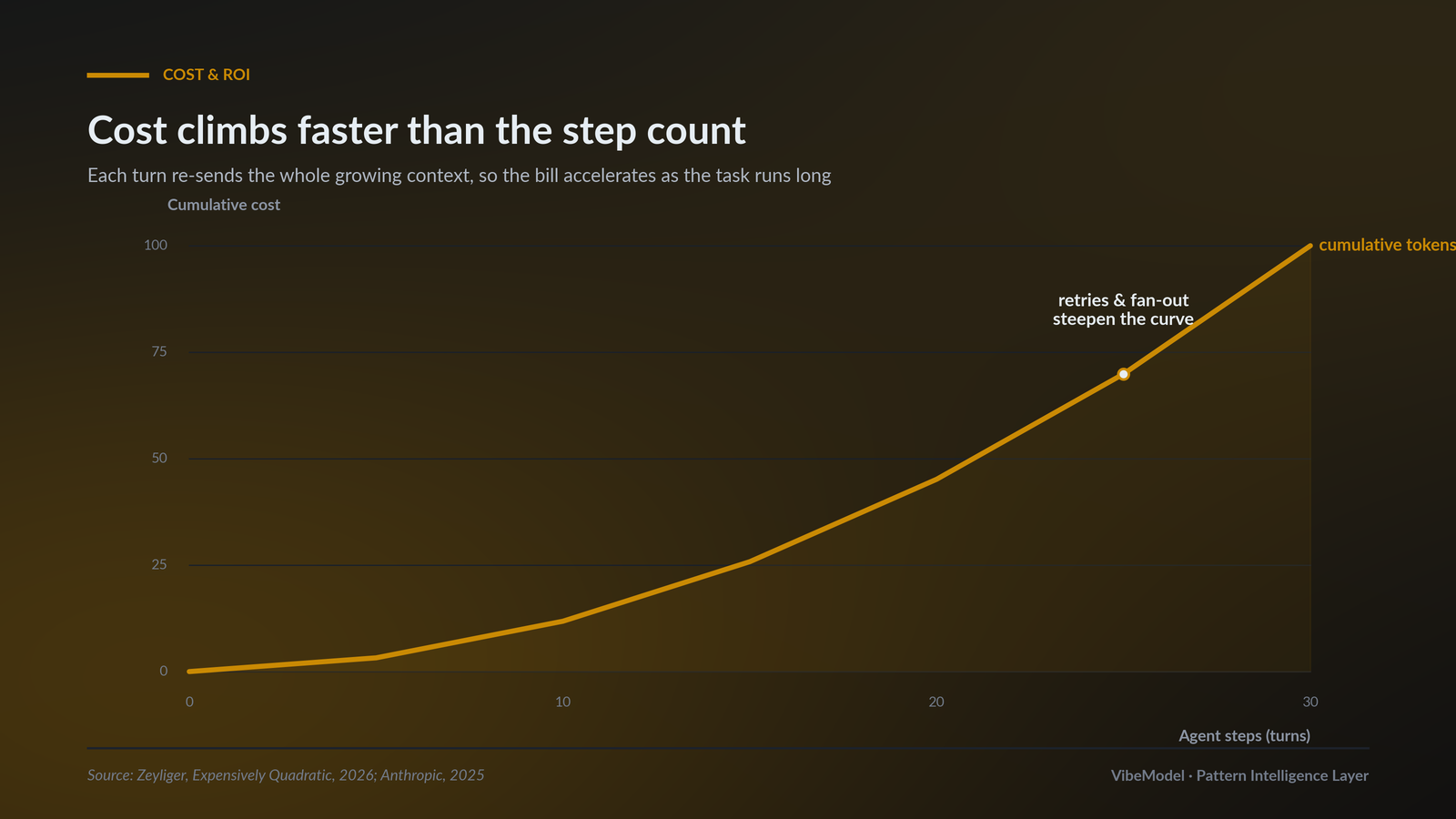
Steps rise in a straight line. Cumulative tokens billed curve upward, because each step re-sends everything before it. Retries and tool fan-out push the same curve higher.
What actually pushes the bill up in production?
Length, multiplied by everything that adds length. Three forces stack on top of the base curve. First, retries: a failed step does not just cost its own tokens, it re-sends all prior context to try again, so one stuck spot can re-bill the whole history several times. Second, tool fan-out: parallel tool calls and subagents each carry their own context, which is exactly how multi-agent systems reach 15x a chat. Third, long-horizon step counts: production tasks simply run for more turns than a demo, and every extra turn re-reads the transcript. None of this is a bug or a pricing trick. Per-token prices have even fallen. The bill rises because autonomous agents on real tasks generate far more turns, and each turn pays to re-read the ones before it.
Which levers actually cut the cost?
| Lever | What it cuts | How |
|---|---|---|
| Scope the context | The re-sent payload | Send each step only what it needs, not the whole transcript |
| Reset the conversation | The compounding history | Start fresh for a new sub-task; re-establishing context is usually cheaper than carrying it |
| Cap retries and steps | Runaway re-billing | Hard limits so one stuck step cannot re-send history endlessly |
| Route by task | Per-token price | Send easy steps to a smaller model; reserve the frontier model for hard ones |
| Offload to tools | Main-context tokens | Do iteration in a tool or subagent so it never enters the main window |
Notice none of these is "buy a cheaper model." The cost was never really about price per token. It was about how much context each step has to carry, and how many steps a task actually runs. So the real question is sharper: for your specific workflow, which steps stay short and cheap, and which ones balloon into the long, retry-heavy, fan-out-heavy paths that drive the bill? Knowing where an agent runs lean and where it runs expensive, before production hands you the invoice, is the pattern-level reliability OptimalARC builds as the Pattern Intelligence Layer.
Frequently asked questions
Why does my agent cost so much more in production than in the demo?
Because production tasks are longer. The demo ran a short happy path; production runs long real paths with retries and tool fan-out. Each turn re-sends the whole prior context, so cost compounds with length. Same price per token, far more tokens.
Will switching to a cheaper model fix it?
Only partly. Routing easy steps to a smaller model lowers price per token, but the main driver is how much context each step re-sends and how many steps run. Cut the context and the step count first; route second.
Why does cost grow faster than the number of steps?
Because every step re-sends all prior context, so billed tokens grow roughly as tokens times calls, not linearly. In one real session, re-read history was 87% of the cost by the end and crossed half the bill at 27,500 tokens.
Is starting a new conversation wasteful?
Usually the opposite. Re-establishing context in a fresh conversation is typically cheaper than carrying a long history that gets re-sent on every turn, and the result is often the same. Reset between sub-tasks.