


Each step looks almost perfect. The small cracks compound down the chain until the whole thing breaks. Reliability multiplies.
Short answer. Because reliability multiplies, it does not average. An agent that is 95% reliable on each step is not 95% reliable overall. Across a 20-step task that is 0.95 to the 20th power, roughly 36% end to end. Small per-step error rates that look excellent in isolation compound into majority failure once the chain is long enough.
Key facts.
- The math is unforgiving: at 95% per-step reliability, a 20-step task succeeds about 36% of the time; even at an unusually high 99% per step, it is only about 82%.
- Success collapses with task length in practice: frontier models hit near-100% on tasks a human finishes in under 4 minutes, but under 10% on tasks taking over about 4 hours (METR, Measuring AI Ability to Complete Long Tasks, 2025).
- A per-step error as small as 0.22% drives near-certain failure after a few hundred steps; decomposition plus per-step voting drove errors to zero across a million steps (MAKER, 2025).
- Multi-agent framework failure rates run 41% to 86.7% (Cemri et al., MAST), and error propagation is identified as the dominant agent failure pattern (AgentErrorBench).
Why does reliability multiply instead of average?
Because a multi-step task only succeeds if every step succeeds. If step one works 95% of the time and step two works 95% of the time, the chance both work is 0.95 times 0.95, about 90%, not 95%. Extend that to twenty steps and you multiply 0.95 by itself twenty times, which lands near 36%. Each step is a gate, and the gates are in series, so their failure probabilities stack. This is the same reason a chain is only as strong as the product of its links, not their average. The per-step number can look excellent while the end-to-end number is a coin flip or worse.
Why does a 95% step rate feel safe but fail in practice?
Because human intuition averages, and the system multiplies. A 95% reliability reads like an A grade, so teams ship it. But an agent does not get partial credit for getting nineteen of twenty steps right; one wrong step derails the task. The longer the workflow, the wider the gap between the comforting per-step number and the brutal end-to-end one. This is why agents demo beautifully on short happy paths and fall apart on real, long tasks: the demo had three steps, production has twenty, and the math turned against you somewhere in between.
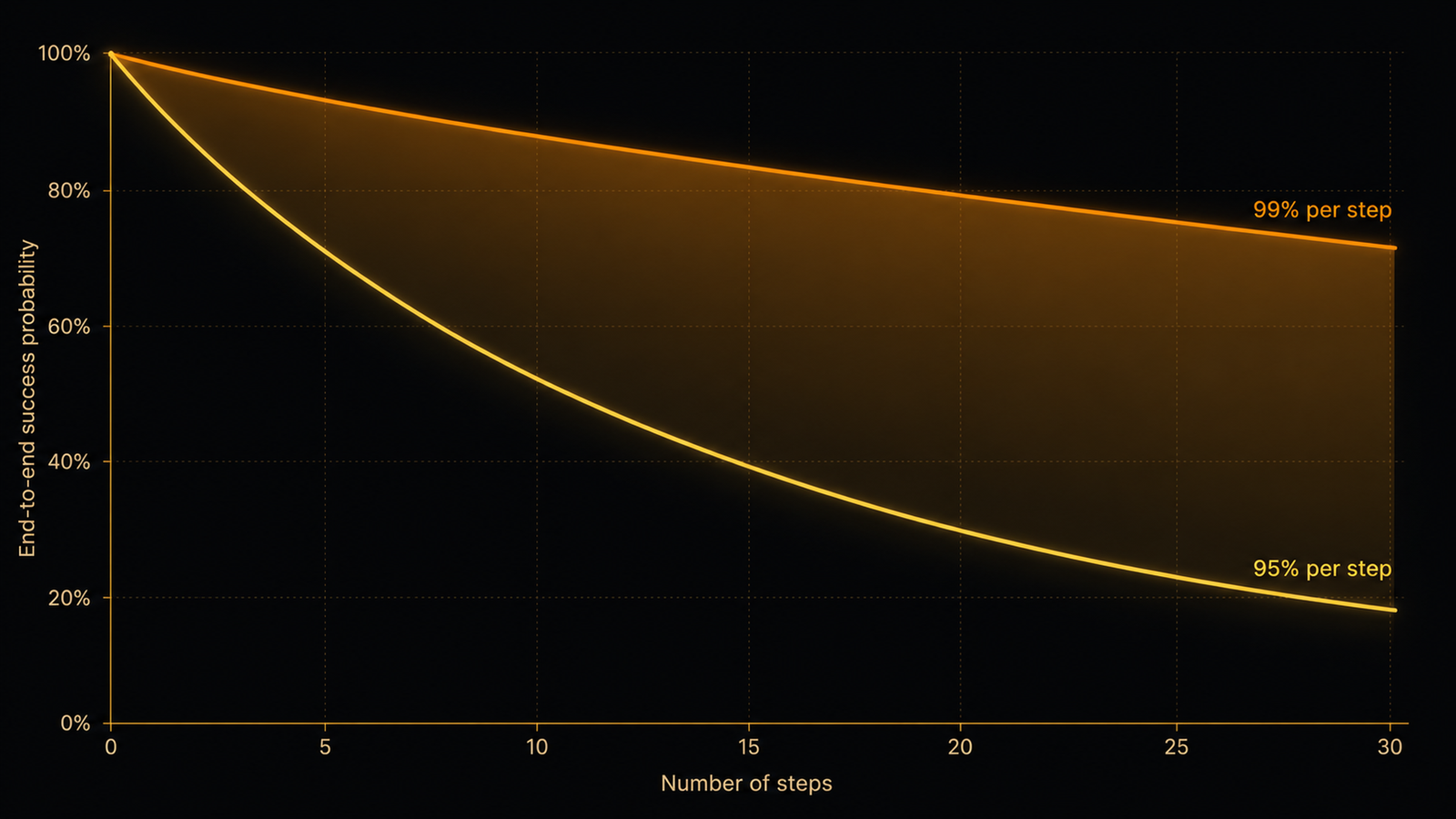
End-to-end success against number of steps. At 95% per step it falls off a cliff; even 99% sags. Length is the enemy.
Why does this hit agents specifically?
Because agents are long chains of probabilistic decisions. Every tool call, every plan step, every handoff is another gate that can fail, and agents string many of them together. A traditional program runs deterministic steps that either work every time or fail loudly; an agent runs steps that each work most of the time, which is exactly the regime where compounding bites hardest. Worse, errors do not just drop a step, they propagate. Each step's output is appended to the context and conditions the next call, so the agent self-conditions on its own mistake, treating a hallucinated value as established fact and building on it. One bad step poisons every downstream decision, which is why the AgentErrorBench analysis names error propagation the single biggest barrier to dependable agents, and why chains often go off the rails by the third bad call. Architecture matters too: one scaling study found decentralized agent setups amplified errors roughly 17 times versus about 4 times for orchestrated ones.
How do you beat the math?
| Lever | Why it works | How |
|---|---|---|
| Fewer steps | Less to multiply through | Decompose less; collapse steps; constrain scope |
| Higher per-step reliability | Each gate leaks less | Better tools, typed contracts, retries with backoff |
| Verification gates | Catch a failure before it compounds | Read-back and checks at each critical step |
| Error recovery | A failed step does not end the task | Detect, correct, and re-attempt instead of propagating |
| Checkpoints | Resume instead of restart | Persist state so one failure is local, not total |
The strategic move is to stop accepting the chain length as fixed. Every step you remove improves the odds geometrically, so the highest-leverage reliability work is often deleting steps, not perfecting them. After that, add verification at the steps that matter so a failure is caught before it multiplies, and build recovery so a single bad step is a local event rather than a total loss. Knowing which steps in your workflow are the weak links, and which are reliable enough to leave alone, is the pattern-level reliability OptimalARC builds as the Pattern Intelligence Layer.
Frequently asked questions
If each step is 95% reliable, why isn't the whole task 95%?
Because the task needs every step to work, and the probabilities multiply. 0.95 across 20 steps is about 36%, not 95%. Reliability in series multiplies; it does not average.
Does a smarter model fix this?
Only partially. A better model raises the per-step rate, which helps, but the multiplication still bites on long tasks. The bigger wins usually come from fewer steps, verification, and error recovery, not just a stronger model.
Why do agents demo well but fail in production?
Demos are short, so the compounding has few steps to act on. Production tasks are long, so the same per-step reliability produces a far lower end-to-end success rate. The math turns against you as the chain grows.
What is the highest-leverage fix?
Cut steps. Because reliability multiplies, removing a step improves success geometrically. Then add verification at the critical steps so a failure is caught before it compounds through the rest.