

Short answer. Your agent gets more expensive over a long run because an LLM has no memory between calls, so the agent re-sends the entire growing conversation on every step. Cost tracks the number of tokens times the number of calls, not the size of the task, so it curves upward as the run goes on. Cache the stable prefix, prune and summarize the rest, and cut needless calls, and the bill stays flat and predictable.

Every step carries everything before it. The history the agent re-reads grows taller and costlier as the run continues. Hero image.
Key facts.
- Cost grows with the history carried, not the work done: because the agent re-sends the whole conversation every step, total spend scales roughly with the number of tokens times the number of calls (Philip Zeyliger, Expensively Quadratic, 2026).
- In one real coding-agent conversation totaling about $12.93, re-reading the cached context reached 87% of the total cost by the end, and was already half the cost at 27,500 tokens (Expensively Quadratic, 2026).
- Caching helps but does not remove the curve: a cache read costs about a tenth of a fresh input token (for example $0.30 versus $3.00 per million on Claude Sonnet), yet on long runs those cheap re-reads still dominate the bill (Anthropic prompt-caching documentation, 2026).
Why does cost grow faster than the work?
Because an LLM has no memory between calls, so the agent re-sends the entire conversation on every single step. Step one pays for a small context. Step fifty pays for everything that happened in the first forty-nine, plus the new turn. Add a step and you do not pay for that step alone, you pay to re-read the whole history again. The result, as the Expensively Quadratic analysis puts it, is that cost tracks the number of tokens times the number of calls, not the size of the task. A ten-step task and a hundred-step task on the same problem are not ten times apart in cost. The longer run re-reads a bigger history more times, and the bill curves upward.
Why does prompt caching change the math?
Because re-reading the same prefix is the expensive part, and caching makes that part cheap. Providers let you cache a stable context prefix and charge a fraction to read it back: on Claude Sonnet a cached read is about $0.30 per million tokens against $3.00 for fresh input, roughly a 90% saving, with a small premium to write the cache (Anthropic prompt-caching documentation). That turns a punishing curve into a manageable one. But it does not flatten it. The Expensively Quadratic data shows cache reads themselves becoming the dominant cost by around 50,000 tokens, reaching 87% of the total in one example. Caching changes the slope, not the shape.
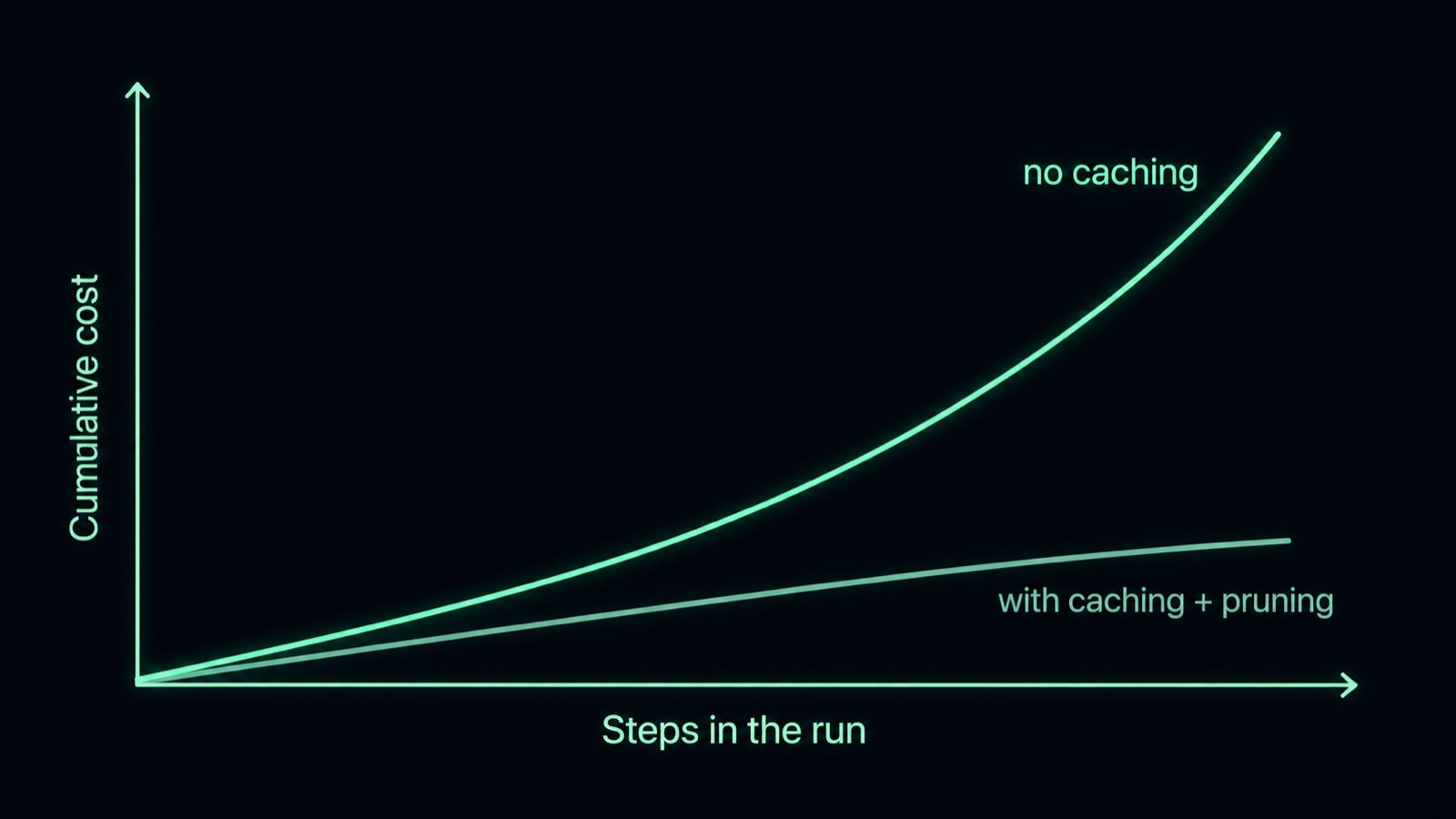
Cost against run length: it steepens as history accumulates. Caching and pruning lower the curve but do not make it flat. Diagram.
So what actually drives the bill on a long run?
Two things, and which one wins shifts as the run grows. Early on, raw context size dominates: every step re-reads a history that keeps getting longer. Past a point, the number of calls takes over. The Expensively Quadratic analysis found that for conversations over about 100,000 tokens, cost is driven more by how many times you call the model than by the raw token count, and that cache reads had already grown to most of the spend. So the expensive agent is rarely the one with a clever prompt. It is the one that loops many times over a fat, ever-growing context, paying to re-read it on each pass.
How do you keep a long agent affordable?
| Lever | What it does |
|---|---|
| Cache the stable prefix | Cuts re-read cost roughly 10x; the single biggest win on long runs |
| Prune the context | Drop old tool outputs and dead reasoning so the history stops growing |
| Summarize and compact | Replace a long transcript with a short running summary on a schedule |
| Cut the number of calls | Fewer, larger steps beat many tiny ones once context is large |
| Cap the working window | Keep the prompt under a budget so cost cannot run away |
| Offload to external state | Store facts outside the prompt and re-inject only what the step needs |
The pattern is that a long agent run pays to re-read its own history, again and again, so cost grows with the history carried rather than the work performed. Cache the stable prefix, prune and summarize the rest, and cut needless calls, and a run that would curve into real money stays flat and predictable. None of that is a bigger model, which only makes each re-read pricier. It is a layer that controls what context the agent carries and how often it pays to re-read it, which is what VibeModel builds as the Pattern Intelligence Layer.
Frequently asked questions
Is the cost really quadratic?
Close enough to feel like it. It is not strictly the square of the tokens; it scales as tokens times calls, because each of the growing steps re-reads the growing history. On a long run that produces the same upward curve you would expect from quadratic growth.
Doesn't a bigger context window help?
No, it makes it worse. A bigger window lets the history grow larger before anything forces you to trim, so each step re-reads more tokens. The fix is to carry less context, not to have room to carry more.
Will prompt caching solve it on its own?
It is the biggest single lever, cutting re-read cost about tenfold, but cache reads still become the dominant cost on long runs. Pair caching with pruning and summarization so the cached prefix itself does not grow without bound.
Where do I look first to cut agent cost?
Cache the stable prefix, then measure how the context grows per step. If it keeps climbing, add pruning and periodic summarization. If you have many short calls over a large context, consolidate them into fewer larger steps.