

Short answer. Your agent takes a wrong action even when the tool worked because the model emitted a malformed call, mis-read a returned field, acted on a truncated payload, or treated an error body as success. These failures raise no exception, so the agent loop continues on corrupted state. Validate the call and the returned body against a typed schema before the agent acts, and the silent failures become loud, catchable ones.

The tool returns cleanly. A broken fragment and a hidden error slip into the agent's next step unflagged. Hero image.
Key facts.
- Even state-of-the-art function-calling agents finish under 50% of realistic tool-use tasks, and consistency across repeated runs collapses (pass^8 under 25% in retail), a gap that compounds every time one tool output feeds the next call (Yao et al., tau-bench, arXiv:2406.12045, 2024).
- A 2025 taxonomy of failures in tool-augmented LLMs treats parsing failures, where a tool call or its returned output cannot be correctly parsed, as a distinct root-cause category, separate from the model reasoning wrong (Winston and Just, A Taxonomy of Failures in Tool-Augmented LLMs, IEEE/ACM AST 2025).
- Parameter-name hallucination is the single biggest driver of multi-turn tool failures; when every parameter name is correct, task accuracy approaches 100% (HammerBench, arXiv:2412.16516, 2024).
- The Berkeley Function-Calling Leaderboard grades each generated call for structural correctness with an abstract-syntax-tree check, and multi-turn scores fall sharply below single-call scores, where one mis-formed or mis-read output derails the rest (BFCL, gorilla.cs.berkeley.edu, 2024-2026).
What does a tool-output parsing failure actually look like?
The model calls a tool, the tool runs fine, and the agent still acts on the wrong thing, because the step between the tool returning and the model reading it broke. It shows up four ways. The agent emits invalid JSON for the call, a missing brace, a trailing comma, Python dict syntax instead of JSON, so the arguments are unusable. The tool returns valid JSON that the agent mis-reads, pulling the wrong field or coercing a string into a number. The output is too long and gets silently clipped, so the model reasons over half a payload. Or the tool returns an error inside a success envelope and the agent treats it as done. None of these throws an exception. The loop continues, the state is now wrong, and the next step inherits it.
Why does a tool call that worked still corrupt the agent?
Because most agent code checks that a call returned, not what it returned. A REST or GraphQL endpoint can answer 200 OK with a body that says success is false and carries an error message inside it. An agent that branches on the status code alone reads that as a completed action and moves on, confidently reporting a refund issued or a record updated that never happened. This is the same silent-success failure that bites verification across agents: the tool layer validates syntax and transport, not outcome. The fix is to make tools return a structured, explicit success-or-error flag, and to have the agent read the body, not the envelope, before it claims anything is done.
# HTTP 200 OK, yet the action never happened { "status": "ok", "data": { "success": false, "error": "insufficient_balance" } } # Branch on the 200 alone and the agent reports "refund issued". It was not.
Why do long tool outputs quietly poison the next step?
Because the dangerous truncation is the one nobody configured. A field analysis from Arize describes agents injecting raw tool results, an 8,000-token HTML page, a giant log, a sprawling JSON, straight into the context, where the model or the framework clips it to fit and the model then reasons over a fragment (Arize, Why AI Agents Break, 2026, reported). The cut usually lands mid-structure, so a record loses a field or a list loses its tail, and the model gap-fills with a plausible wrong value rather than flagging the gap. The output looked successful. It was just incomplete by the time the model saw it. Summarize or paginate large tool results, and stamp them with a clear truncation marker so the model knows data is missing.
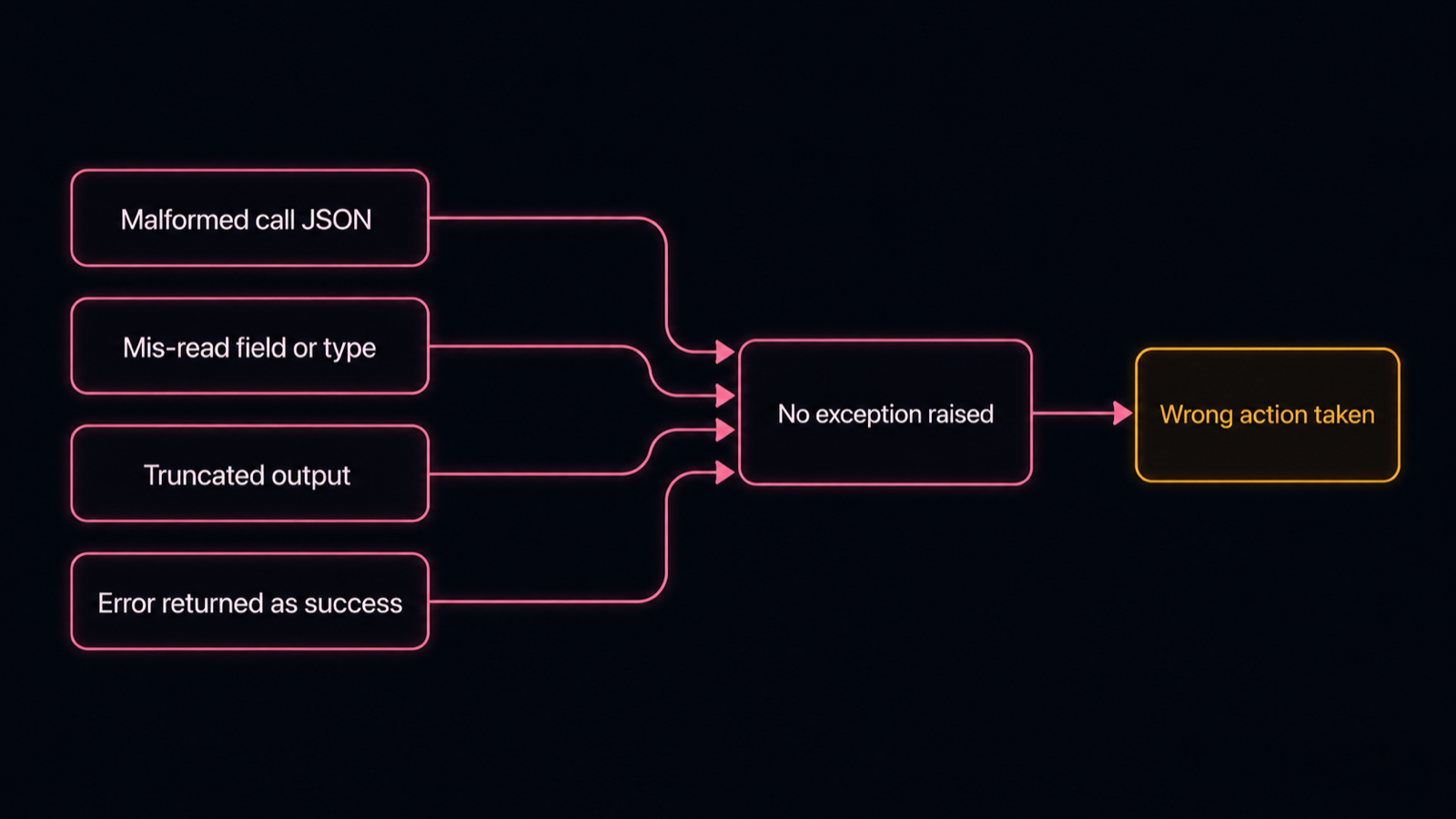
Four ways the seam between tool and model breaks, all converging on a wrong action that raises no error. Diagram.
Why doesn't a bigger model fix this?
Because the model is a next-token predictor, not a guaranteed parser, and the failures live in the seams between probabilistic generation and rigid downstream code. The benchmarks make the size of the gap concrete. On in-the-wild tool orchestration, no mainstream model clears 15% session accuracy, with the errors broken into type errors, value errors, and hallucinated parameters (WildToolBench, arXiv:2604.06185, 2026). tau-bench shows the same agents that look strong on a single call dropping under 50% on realistic multi-turn tasks and under 25% consistency across repeats. A stronger model nudges these numbers, but it does not turn a malformed payload into a valid one or make a swallowed error surface. That is engineering, not model scale.
How reliable is function calling really?
Better than it was, and still not safe to trust blind. Native function calling and strict structured outputs, where the model is constrained to a JSON schema, sharply cut malformed-JSON rates, and on the Berkeley leaderboard the best models land in the high-70s percent overall on call correctness. But the same board shows multi-turn and agentic scores well below single-call scores, and HammerBench shows accuracy swinging from near-perfect to poor purely on whether parameter names are clean. So schema-constrained generation is necessary and not sufficient. You still validate every argument and every returned body against a typed schema before the agent is allowed to act on it.
How do you stop it?
| Failure mode | What you see | Fix |
|---|---|---|
| Malformed call JSON | Args unusable, parse error or silent drop | Native function calling + strict structured outputs |
| Mis-read field or type | Wrong value, no error raised | Validate the returned body with a typed schema (Pydantic) |
| Error-as-success | "Done" on an action that failed | Read the body, require an explicit success/error flag |
| Truncated long output | Confident but incomplete answer | Summarize or paginate, mark the truncation |
| Param-name hallucination | Multi-turn failures, wrong tool wiring | Constrained names, validation, a JSON repair loop |
The pattern under every one of these is that a tool returning is not a tool succeeding. Constrain the call to a schema, validate the returned body before the agent acts, read the contents instead of the status code, and bound and mark long outputs so nothing gets clipped in silence. None of that is a smarter model. It is a verification layer that treats every tool result as a claim to be checked rather than a fact to be trusted, which is what VibeModel builds as the Pattern Intelligence Layer.
Frequently asked questions
Doesn't strict JSON mode or function calling already solve this?
It solves the front half, the shape of the call the model emits, and that matters. It does nothing for the back half: a syntactically valid response whose body reports an error, carries the wrong field, or arrives truncated. You still validate the returned content before acting.
How is this different from the agent just hallucinating?
Hallucination is the model inventing an answer. This is the plumbing between a correctly run tool and the model corrupting otherwise good data: a mis-parsed field, a swallowed error, a clipped payload. A 2025 taxonomy of tool-augmented LLM failures treats parsing failures as their own class for exactly that reason.
What is the single highest-impact fix?
Validate every tool response against a typed schema with an explicit success flag before the agent is allowed to act, and never branch on the HTTP status code alone. That one gate catches error-as-success, mis-read fields, and most truncation.
How do I catch these in production?
Trace the raw tool request and response and record parse-success and validation-pass rates per tool. The failures are invisible in the final answer but obvious in the trace: an error body marked done, a response that failed schema validation but still advanced the loop.