

Short answer. Your reranker hurts results when it is fed too many candidates or tuned to keep too few: it starts scoring irrelevant documents highly and discarding relevant ones the retriever correctly found, so recall falls below the plain retriever. Rerank a small shortlist, tune the cutoff against a recall floor, and prefer a calibrated specialized reranker, and you get the precision without the recall loss.

A reranker reorders what the retriever found. Tuned wrong, it promotes the wrong items and drops the right one. Hero image.
Key facts.
- Reranking is meant to add precision, but past a point it removes good results: when rerankers score large candidate sets, recall drops, often below the plain retriever, across a large share of tested datasets (Drowning in Documents, arXiv:2411.11767, SIGIR ReNeuIR 2025).
- The mechanism is phantom hits: rerankers assign very high scores to documents with no real lexical or semantic match to the query, the same documents the retriever correctly scored low (Drowning in Documents, 2025).
- A bigger model is not automatically a better reranker: across 13 datasets, an LLM-as-reranker on a strong first stage sometimes lowered NDCG@10 below the no-rerank baseline, while a specialized reranker ran up to 60 times cheaper and 48 times faster (Voyage AI, The Case Against LLMs as Rerankers, 2025).
What does a reranker actually do, and when does it backfire?
A reranker is a second-stage model that re-scores the documents your retriever already fetched, so the most relevant ones rise to the top of the context. Used well, it buys precision: the retriever casts a wide net for recall, the reranker sharpens the order. It backfires two ways. If you set the keep-threshold too aggressively, the reranker discards relevant chunks the retriever correctly found, and recall falls. And if you feed it too many candidates, its scores get noisy and it starts promoting documents that do not belong. The reranker was added to improve quality. Misconfigured, it is now the stage that throws away the right answer, and it does so silently, because the final answer still reads fluent.
Why does reranking more documents make recall worse?
Because rerankers do not degrade gracefully as the candidate pool grows. The Drowning in Documents study scaled the number of reranked candidates and found that recall climbs at first and then falls, often dropping below the standalone retriever once the pool gets large (arXiv:2411.11767). The cause is phantom hits: the reranker assigns very high scores to documents with no real lexical or semantic relationship to the query, the same documents the retriever had correctly ranked near the bottom. Scale the candidate set to thousands, expecting safety in breadth, and you instead hand the reranker more chances to invent relevance. More documents reranked is not more recall. Past a point it is less, which is the opposite of what the stage was added to do.
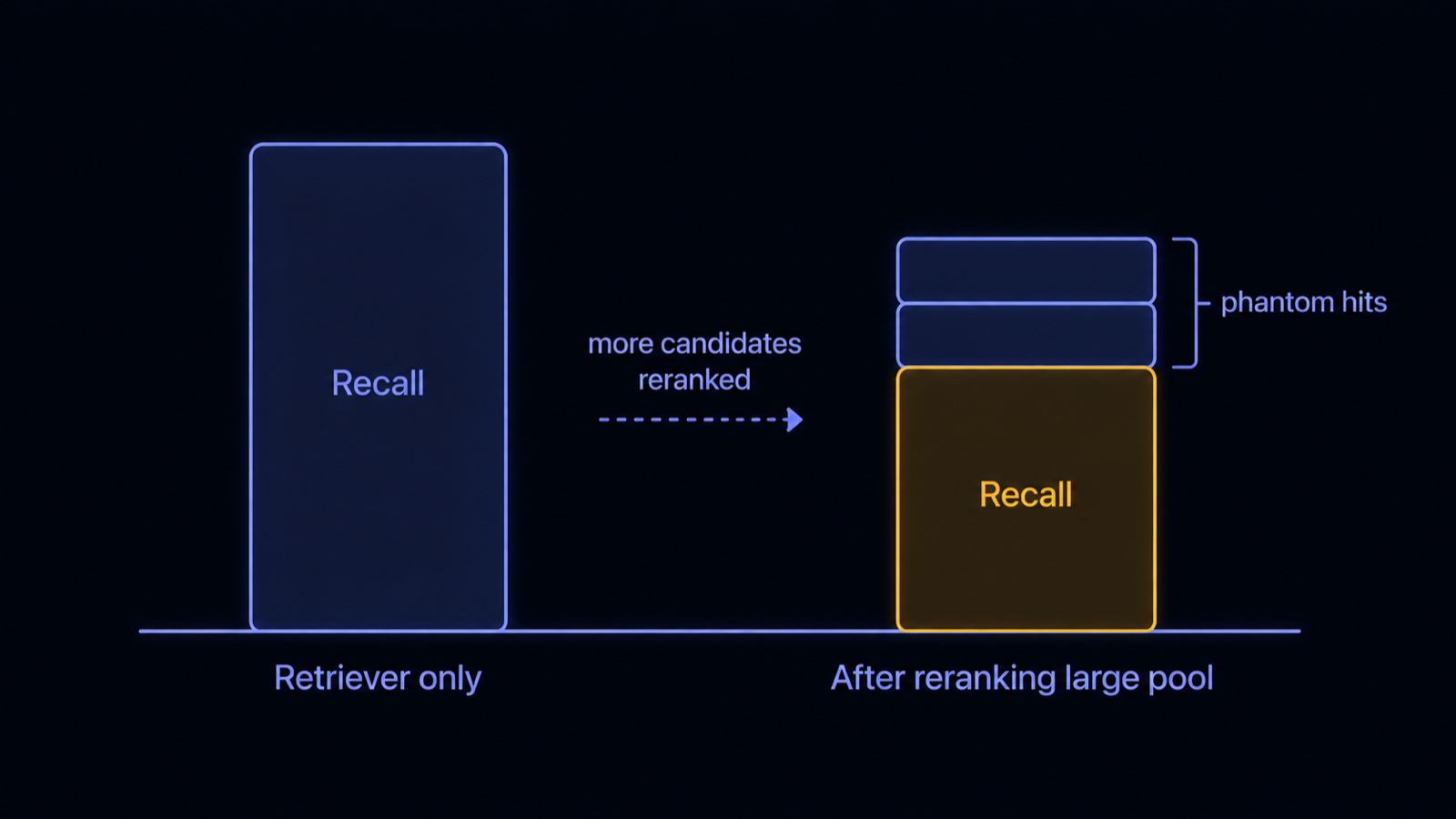
Recall before and after reranking a large pool: the reranker promotes phantom hits and falls below the plain retriever. Diagram.
Why can an LLM reranker underperform a cheap specialized one?
Because general capability is not ranking calibration. Voyage AI compared LLM-as-rerankers against specialized rerankers across 13 datasets and found that on a strong first-stage retriever, the LLM sometimes pushed NDCG@10 below the no-rerank baseline, while a purpose-built reranker ran up to 60 times cheaper and 48 times faster (The Case Against LLMs as Rerankers, 2025). LLM rerankers are also unusually sensitive to how you present the candidates: feeding them as one long context underperformed a sliding-window approach by 22 to 26.6%, so the same documents in a different order produced a different ranking. A reranker whose output swings with input order is adding variance, not precision.
When does reranking actually help?
When the first-stage retriever is weak and the candidate set is small. The same studies that show reranking hurting at scale show it helping where there is real headroom: on weaker retrievers, specialized rerankers gave large gains, and rerankers improve recall at small K in most experiments. The decision is not reranker or no reranker. It is matching the reranker to the gap. If your retriever is already strong and you are reranking thousands of candidates, you are in the regime where reranking degrades. If your retriever is noisy and you rerank a tight shortlist, you are in the regime where it pays off, which is most production RAG done well.
How do you rerank without losing recall?
| Symptom | Cause | Fix |
|---|---|---|
| Recall drops after adding a reranker | Keep-threshold too aggressive | Tune the cutoff on offline eval, hold a recall floor |
| Worse than no reranker at scale | Phantom hits at large K | Rerank a small shortlist (tens), not thousands |
| Ranking unstable run to run | LLM order and format sensitivity | Use a specialized reranker; fix candidate order |
| Slow and costly | LLM reranker overhead | Calibrated cross-encoder, far cheaper and faster |
| Helps in eval, hurts in prod | Untuned for your domain | Monitor Recall@K in production, not just precision |
The pattern is that a reranker is a precision tool with a recall cost, and the cost is invisible until you measure it. Keep the candidate set small, tune the threshold against a recall floor, prefer a calibrated specialized reranker over a general model, and watch recall in production, not just precision in a benchmark. None of that is a bigger model. It is knowing the regime your retrieval is in and ranking for it, which is what VibeModel builds as the Pattern Intelligence Layer.
Frequently asked questions
Should I just remove the reranker?
No. Reranking helps when the retriever is weak and you rerank a small shortlist. The fix is to use it in that regime, not to drop it. Removing it blindly can lose precision just as adding it blindly can lose recall.
More candidates sounds safer. Why does reranking more of them hurt?
Because rerankers produce phantom hits, scoring truly irrelevant documents highly. The more candidates you feed, the more chances to promote one of those over a real result, which is why recall falls below the plain retriever at large K.
Is an LLM reranker better than a cross-encoder?
Not reliably. On strong retrievers an LLM reranker sometimes scored below the no-rerank baseline and was far slower and costlier, and its ranking shifted with input order. A calibrated specialized reranker is usually the safer, cheaper choice.
How do I catch reranker-caused recall loss?
Measure Recall@K with and without the reranker on your own data, at the candidate-set size you actually use in production. If reranking lowers recall, your shortlist is too large or your threshold too tight.