

Short answer. Your RAG returns half-answers because fixed-size chunking cuts documents at arbitrary boundaries, severing a fact from the context that makes it usable, so retrieval hands the model a fragment. Split at meaning instead of token counts, keep tables and sections intact, overlap the boundaries, and retrieve on small chunks but read the larger parent, and the facts stay whole from source to answer.

A rigid fixed-size grid slices straight through a sentence and a table. The halves drift apart, and retrieval only ever finds one. Hero image.
Key facts.
- The strategy can swamp everything else: a clinical-RAG study found chunking aligned to logical topic boundaries hit 87% accuracy versus 13% for a fixed-size baseline on the same documents (MDPI Bioengineering, 2025).
- It shows up as recall: fixed-size chunking scored 0.40 recall against 0.75 for semantic chunking in the same evaluation, so the fixed-size pipeline failed to retrieve the relevant material far more often (same study, 2025).
- There is no single right size: NVIDIA's 2024 evaluation of seven chunking strategies across five datasets found the best size depends on the query, with factoid questions favoring 256 to 512 tokens and analytical questions needing 1024 or more (NVIDIA, 2024).
What does bad chunking actually do?
It cuts facts in half. Before anything is retrieved, your documents are split into chunks, and a fixed-size splitter cuts at arbitrary token boundaries with no regard for meaning. So a rule lands in one chunk and its exception in the next, a table row gets separated from its header, a definition is split from the term it defines. Retrieval then returns one half, and the model answers from a partial truth, confidently. The source contained the whole fact. The chunker severed it before the retriever ever saw it, which is why the agent gives a half-answer that is technically grounded in your data and still wrong.
# A fixed 256-token split lands mid-rule. Two chunks, neither complete: --- chunk 41 --- "Returns are accepted within 30 days of delivery, --- chunk 42 (boundary cut here) --- except for final-sale items, which are non-refundable." # Retrieve chunk 41 and the agent says "30-day returns", missing the exception.
Why is one chunk size always wrong?
Because a single chunk is asked to do two jobs that pull in opposite directions. Retrieval matching wants small, focused chunks: a tight 100-to-256-token passage has one clear topic, so its embedding is sharp and the retriever finds it. Context completeness wants large chunks: the model needs enough surrounding text, a thousand tokens or more, to use the fact without missing a caveat. A fixed size cannot be both. Pick it small and you retrieve well but hand the model fragments; pick it large and each chunk is a blurry mix of topics the retriever struggles to match. This is the structural conflict at the heart of the naive chunk-embed-retrieve pipeline, and it is why one global chunk size is always a compromise.
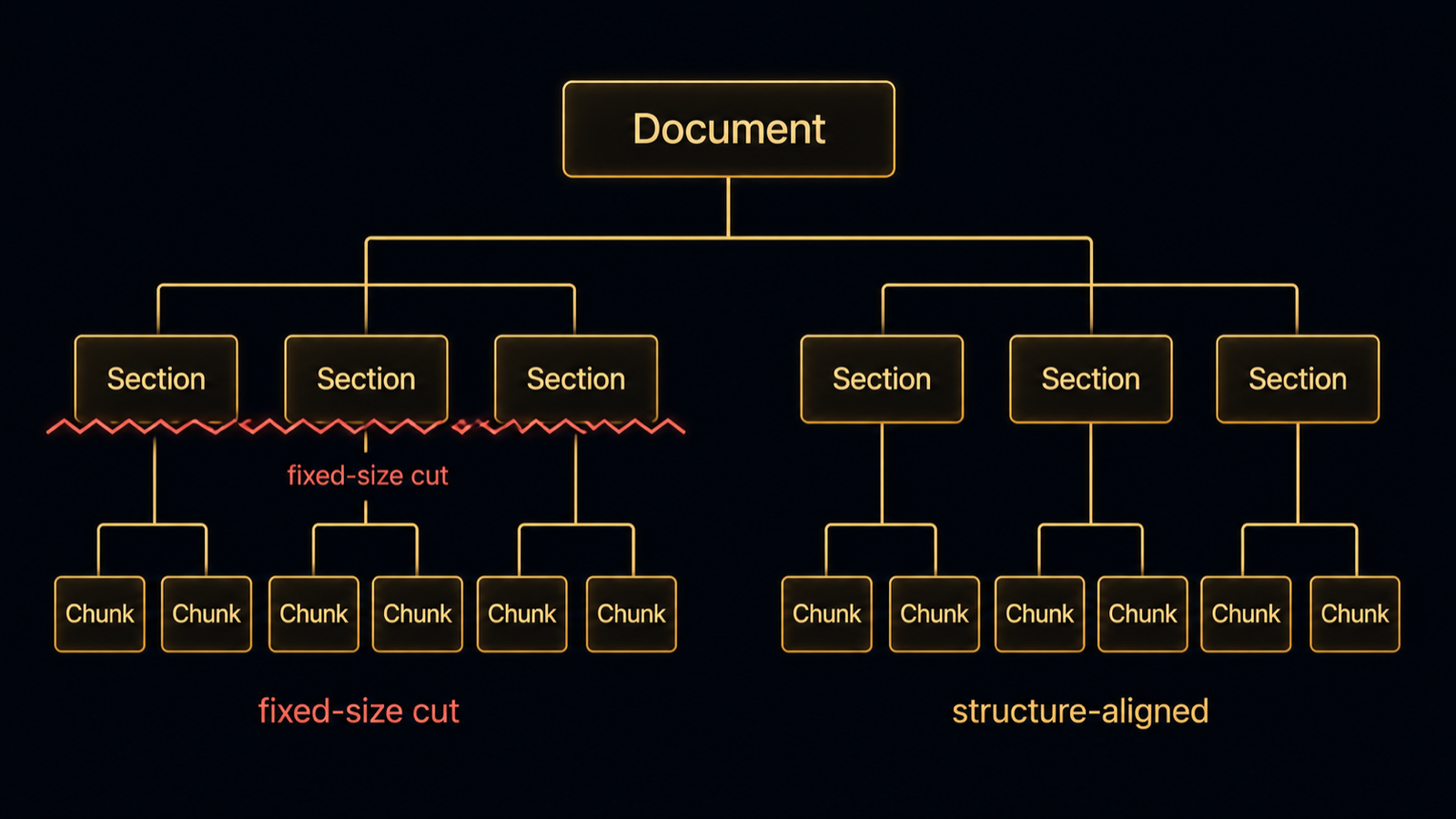
Document to section to chunk: a structure-aligned split keeps a fact whole, while a fixed-size cut slices straight across the boundary. Diagram.
How big is the gap?
Large enough to dominate everything downstream. In a clinical decision-support evaluation, chunking aligned to logical topic boundaries reached 87% accuracy while a fixed-size baseline managed 13% on the same documents, and recall told the same story: 0.75 for semantic chunking against 0.40 for fixed-size. The right size also depends on the question. NVIDIA's evaluation across seven strategies and five datasets found factoid queries did best at 256 to 512 tokens while analytical queries needed 1024 or more, and page-level chunking was a strong general default. The takeaway is not a magic number. It is that chunking is a first-class design decision, and getting it wrong caps your accuracy no matter how good your model or retriever is.
How do you chunk so facts stay whole?
| Technique | What it does |
|---|---|
| Semantic / structure-aware chunking | Split at topic, section, and document boundaries, not token counts |
| Respect tables and lists | Keep a row with its header and an item with its context |
| Add overlap | Let chunks share a window so a fact split at a boundary survives in one of them |
| Attach metadata | Tag each chunk with its source, section, and date for filtering and grounding |
| Parent-document retrieval | Match on small chunks, then return the larger parent for context |
| Late chunking | Embed the long document first, then chunk, so each chunk keeps document context |
The pattern is that retrieval can only return what chunking left whole, and a fixed-size splitter routinely cuts facts in half before the model ever sees them. Split at meaning, keep structure intact, overlap the boundaries, and retrieve small but read large with parent-document or late chunking. None of that is a bigger model, which only paraphrases the fragment more fluently. It is a data layer that keeps facts intact from source to context, which is what VibeModel builds as the Pattern Intelligence Layer.
Frequently asked questions
Isn't this fixed by a bigger context window?
No. The damage happens at retrieval: if the chunk that was fetched is a fragment, a bigger window just holds a bigger fragment. You have to chunk so the whole fact is retrievable in the first place, then use the window to read it in full context.
What chunk size should I use?
It depends on the query. Factoid lookups do well around 256 to 512 tokens; analytical questions need 1024 or more. Rather than pick one, retrieve on small chunks and return the larger parent, so you get sharp matching and full context.
What's the single highest-impact change?
Stop splitting at fixed token counts. Switch to structure-aware chunking that respects sections, tables, and topic boundaries, and add overlap. That alone closes most of the gap between a 13% and an 87% pipeline.