

Short answer. Your agent keeps acting on a wrong fact because that fact got written into its state, the scratchpad, the running context, or a persistent memory store, and nothing tags it as unverified. Every later step retrieves it and treats it as ground truth, so one early error compounds across the run. Stamp state with provenance, verify before you store, and expire stale memory, and a single bad entry stops poisoning everything after it.

One corrupted record in the memory store, spreading its influence outward to everything retrieved after it. Hero image.
Key facts.
- An attacker who can only send normal queries can poison an agent's long-term memory: the MINJA attack reached a 98.2% average injection success rate, slipping malicious records into the store that are retrieved and acted on later, while task utility barely moved, under 2% (Dong et al., MINJA, arXiv:2503.03704, NeurIPS 2025).
- Once poisoned, the bad record drives real actions: MINJA's average attack success rate was 76.8%, reaching 90 to 100% on some agents (MINJA, 2025).
- Corruption is not only malicious: a multi-agent failure study names loss of conversation history, state lost or truncated mid-run, as its own failure mode across seven frameworks (Cemri et al., MAST, arXiv:2503.13657, 2025).
What is state or memory corruption in an agent?
An agent carries state: a scratchpad of intermediate reasoning, the running context, and often a persistent memory store it writes to and reads back across sessions. Corruption is when something false or malformed gets written into that state, and every later step treats it as fact. The bad entry can arrive three ways. The agent hallucinates a value early and records it. A tool returns a malformed or wrong result that gets stored. Or an attacker plants a record on purpose. However it arrives, the moment it is in the agent's memory it stops looking like a guess and starts looking like ground truth, because agent memory has no built-in notion of where a fact came from or how much to trust it.
Why does one bad entry poison every later step?
Because agents lack provenance, verification, and decay for their own state. A person keeps a rough sense of which beliefs are solid and which are hunches; a default agent does not. Once a claim is in the context or the memory store, it is retrieved by similarity and fed back into reasoning with the same weight as a verified fact. This is context poisoning: an early error reproduces at every subsequent step, and because each step builds on the last, the corruption compounds rather than washing out. The agent is not repeatedly making the same mistake. It made one mistake, wrote it down, and is now faithfully reading it back.
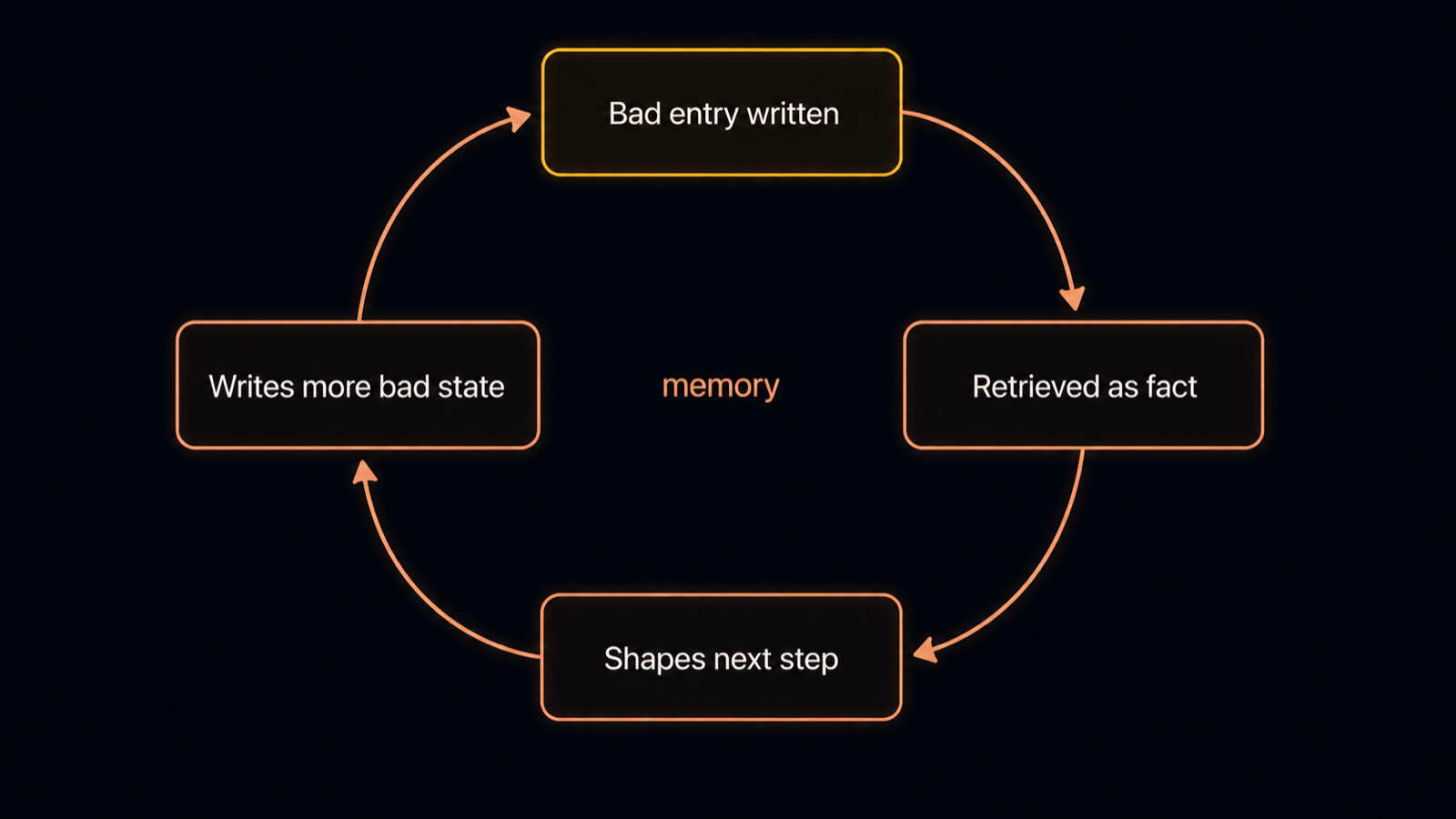
The corruption loop: a bad entry is stored, retrieved as fact, shapes the next step, and writes more bad state. Diagram.
Can someone poison an agent's memory on purpose?
Yes, and it is easier than it sounds. The MINJA attack showed that an adversary who can only send ordinary queries, with no direct access to the database, can still get malicious records written into an agent's long-term memory, then have them retrieved later to steer its behavior. It reached a 98.2% injection success rate and a 76.8% attack success rate, up to 90 to 100% on some agents, while normal task performance dropped under 2%, so nothing looked wrong (arXiv:2503.03704). The memory store is an attack surface, not just a convenience, and an agent that writes untrusted interactions straight into durable memory is one crafted conversation away from being steered.
How do you keep state clean?
Treat agent memory like untrusted input that must earn its place. Tag every stored item with provenance, where it came from and whether it was verified, and let the agent weight a verified fact above a guess. Validate tool results before they are written to state, so a malformed or wrong output never becomes a stored truth. Expire or re-check old memory rather than trusting it forever. Isolate and scope memory per user and per task so one poisoned conversation cannot bleed into others. And keep a clean copy of the original goal and key facts outside the mutable scratchpad, so a corrupted working state can be reset against a trusted baseline. None of that is a bigger model. It is a layer that knows which of the agent's beliefs are earned and which are guessed, which is what VibeModel builds as the Pattern Intelligence Layer.
Frequently asked questions
Is this the same as the agent hallucinating?
Hallucination is the source of one bad entry. Corruption is what happens next: that entry is written to state and read back as fact at every later step, so a single hallucination becomes a persistent, compounding error rather than a one-off.
How is memory poisoning different from prompt injection?
Prompt injection steers the agent in the moment. Memory poisoning is durable: a malicious record is stored and retrieved on future, unrelated tasks, so the influence outlives the conversation that planted it. MINJA showed it works with query-only access.
What is the first thing to fix?
Stop writing unverified content to durable memory. Validate tool results and tag provenance before anything is stored, and keep the original goal in a clean, read-only slot so a corrupted scratchpad can be reset against it.